데이터 전처리란?
본격적으로 R을 이용하여 데이터를 다루기 위해 가장 먼저해야할 과정은 외부에서 Raw data를 가져와서 분석하기 좋은 형태로 데이터를 다듬는 일이다.
Raw data의 형태는 워낙 다양하고 정돈되어 있지 않은 경우가 많다.
그래서 대부분의 분석가들은 데이터분석의 전체 과정에서 최소 반절 이상의 시간을 데이터를 분석하기 좋은 형태로 다듬는데에 사용하며 이러한 과정을 데이터 전처리라고 한다.
간단한 예로, 아래의 데이터시트는 병원에 방문한 환자에 대한 정보를 포함하는 데이터이다.
알러지의 유무(G열 Allergies)를 보면 yes, no를 대소문자를 혼용해서 사용하였다.
사람은 대소문자가 어떻게 되어있던 원하는 정보를 바로 판단할 수 있지만, 컴퓨터로 분석하기 위해서는 이러한 세세한 차이들을 프로그램이 인식할 수 있도록 다듬는 작업이 필요하다.

이러한 데이터 전처리들을 위해서 R유저들은 'tidyverse' 라는 강력한 패키지를 주로 사용한다.
이번 포스팅에서는 tidyverse패키지를 이용하여 데이터를 다듬는 기본적인 테크닉들을 알아보도록 하겠다.
tidyverse 패키지란!
tidyverse라는 이름은 정돈하다의 뜻인 tidy와, universe의 verse를 혼합한 이름으로 보인다.
tidyverse는 하나의 패키지라기 보다 데이터를 정돈하는데 필요한 모든것을 모아둔 패키지의 집합체이다.
tidyverse내에 포함되어있는 패키지들은 모두 같은 문법, 정규포현식(regular expression), 데이터 구조등을 공유한다.
| readr | 자료 불러오기 |
| ggplot2 | 데이터 시각화 |
| dplyr | 데이터 조작 |
| stringr | 문자열 조작 |
| forcats | factor 조작 |
| tibble | 개선된 데이터 프레임 표현 |
| tidyr | 데이터 정돈 |
| purrr | 함수형 프로그래밍 |
tidyverse에 포함된 주요 패키지들
먼저 패키지를 설치하자.
패키지 설치방법은 간단하다.
원하는 패키지 이름을 알고있다면, install.packages("패키지이름") 명령어를 입력하면 자동으로 설치된다.
install.packages("tidyverse") |
위와같은 명령어를 입력하여 tidyverse를 설치하자.
R studio를 사용하고 있다면 오른쪽 아래의 Packages 탭에서 Install을 클릭하여 패키지 이름을 입력하여 설치할 수도 있다.

패키지에 대한 더 자세한 설명은 아래 링크 참고.
2021/01/13 - [지식/R 프로그래밍] - R 프로그래밍 기초_패키지 (Package)
설치를 완료했다면 라이브러리에서 tidyverse를 불러오자.
library(tidyverse) |
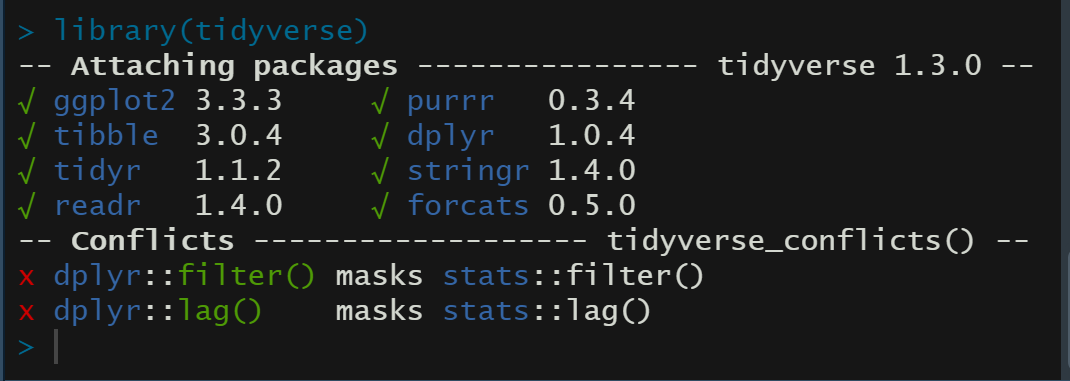
tidyverse에 속해있는 패키지들과, 기존의 충돌이 일어난 명령어들을 보여준다.
데이터 불러오기!
R을 통해 데이터를 작업하기 위해서 가장 먼저 할일은 물론 외부 데이터를 Rstudio에 불러오는 일이다.
다음은 한 병원의 방문자에 대한 정보를 예로 사용하였다.

| visit <- read_excel("MedData.xlsx", sheet = "Visits") visit |
엑셀 데이터를 불러오기 위해서는 'read_ecxel' 명령어를 사용하면 된다.
이외에 다른 형태의 텍스트 파일을 불러오기 위해서 read.table, read.csv, read.dcf 등 다양한 커맨드를 필요에 따라 사용할 수 있다.
파일을 그대로 불러왔더니 엑셀파일 맨 위의 3줄의 주석이 테이블에 포함되고, 어디까지가 데이터인지 몰라 17행 이하는 모두 NA로 표시되었다.

이를 해결하기 위해 read_excel 커맨드에 첫 3줄을 제외하라는 커맨드 (skip = 3)와, 13개의 행만 사용하라는 커맨드 (n_max = 13) 를 추가하였다.
| visit <- read_excel("MedData.xlsx" sheet = "Visits", skip = 3, n_max = 13) , sheet = "Visits") visit |

이제 필요한 데이터를 불러온 것 같다.
불러온 데이터셋의 구조를 보기 위해서는 str( ) 또는 glimpse( ) 등의 명령어를 이용할 수 있다.
| str(visit) glimpse(visit) |

한편, 데이터 수치들 중에는 비어있는 값을 빈칸이나, NA ,N/A 등 다양하게 표시해놓은 경우가 있을 수 있다.
이런 경우는 이후 작업에서 원하는 결과를 얻는데 방해가 된다.
예를들어, 위 데이터셋에서 DBP라는 행의 최소값을 보기 위해 min( ) 함수를 이용하면 아래와 같이 '##N/A'라고 표시된다. 엑셀 만든사람이 중간에 빈 값을 ##N/A라고 써놨기 때문이다.
| min(visit$DBP) |

이런 경우 데이터를 불러올때 R에서 빈 값이라는 것을 알려주기 위해 na = 명령어를 추가할 수 있다.
빈칸, NA, ##N/A 세가지 를 빈 값으로 인식하게 하고 싶다면 na=c("","NA","##N/A")) 를 입력하면 된다.
| visit <- read_excel("MedData.xlsx", sheet = "Visits", skip = 3, n_max = 13, na=c("","NA","##N/A")) min(visit$DBP, na.rm = TRUE) |
'지식 > R 프로그래밍' 카테고리의 다른 글
| R 프로그래밍 기초_R 자료형과 데이터 구조 (0) | 2021.01.20 |
|---|---|
| R 프로그래밍 기초_기본 R 명령어 모음 (0) | 2021.01.19 |
| R 프로그래밍 기초_그래프 그리기 기본<plot> 의 모든것 (0) | 2021.01.18 |
| R 프로그래밍 기초_패키지 (Package) (0) | 2021.01.13 |
| R 프로그래밍 기초_기본 인터페이스 (0) | 2021.01.09 |




댓글